Consistent estimator
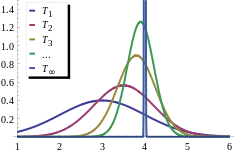
T1, T2, T3, ... is a sequence of estimators for parameter θ0, the true value of which is 4. This sequence is consistent: the estimators are getting more and more concentrated near the true value θ0; at the same time, these estimators are biased. The limiting distribution of the sequence is a degenerate random variable which equals θ0 with probability 1.
In statistics, a consistent estimator or asymptotically consistent estimator is an estimator—a rule for computing estimates of a parameter θ0—having the property that as the number of data points used increases indefinitely, the resulting sequence of estimates converges in probability to θ0. This means that the distributions of the estimates become more and more concentrated near the true value of the parameter being estimated, so that the probability of the estimator being arbitrarily close to θ0 converges to one.
In practice one constructs an estimator as a function of an available sample of size n, and then imagines being able to keep collecting data and expanding the sample ad infinitum. In this way one would obtain a sequence of estimates indexed by n, and consistency is a property of what occurs as the sample size “grows to infinity”. If the sequence of estimates can be mathematically shown to converge in probability to the true value θ0, it is called a consistent estimator; otherwise the estimator is said to be inconsistent.
Consistency as defined here is sometimes referred to as weak consistency. When we replace convergence in probability with almost sure convergence, then the estimator is said to be strongly consistent. Consistency is related to bias; see bias versus consistency.
Contents
1 Definition
2 Examples
2.1 Sample mean of a normal random variable
3 Establishing consistency
4 Bias versus consistency
4.1 Unbiased but not consistent
4.2 Biased but consistent
5 See also
6 Notes
7 References
8 External links
Definition
Loosely speaking, an estimator Tn of parameter θ is said to be consistent, if it converges in probability to the true value of the parameter:[1]
- plimn→∞Tn=θ.displaystyle underset nto infty operatorname plim ;T_n=theta .

A more rigorous definition takes into account the fact that θ is actually unknown, and thus the convergence in probability must take place for every possible value of this parameter. Suppose pθ: θ ∈ Θ is a family of distributions (the parametric model), and Xθ = X1, X2, … : Xi ~ pθ is an infinite sample from the distribution pθ. Let Tn(Xθ) be a sequence of estimators for some parameter g(θ). Usually Tn will be based on the first n observations of a sample. Then this sequence Tn is said to be (weakly) consistent if [2]
- plimn→∞Tn(Xθ)=g(θ), for all θ∈Θ.displaystyle underset nto infty operatorname plim ;T_n(X^theta )=g(theta ), textfor all theta in Theta .

This definition uses g(θ) instead of simply θ, because often one is interested in estimating a certain function or a sub-vector of the underlying parameter. In the next example we estimate the location parameter of the model, but not the scale:
Examples
Sample mean of a normal random variable
Suppose one has a sequence of observations X1, X2, ... from a normal N(μ, σ2) distribution. To estimate μ based on the first n observations, one can use the sample mean: Tn = (X1 + ... + Xn)/n. This defines a sequence of estimators, indexed by the sample size n.
From the properties of the normal distribution, we know the sampling distribution of this statistic: Tn is itself normally distributed, with mean μ and variance σ2/n. Equivalently, (Tn−μ)/(σ/n)displaystyle scriptstyle (T_n-mu )/(sigma /sqrt n)
- Pr[|Tn−μ|≥ε]=Pr[n|Tn−μ|σ≥nε/σ]=2(1−Φ(nεσ))→0geq varepsilon ,right]=Pr !left[frac sqrt n,T_n-mu sigma geq sqrt nvarepsilon /sigma right]=2left(1-Phi left(frac sqrt n,varepsilon sigma right)right)to 0
![Pr !left[,|T_n-mu |geq varepsilon ,right]=Pr !left[frac sqrt n,T_n-mu sigma geq sqrt nvarepsilon /sigma right]=2left(1-Phi left(frac sqrt n,varepsilon sigma right)right)to 0](https://wikimedia.org/api/rest_v1/media/math/render/svg/1427f3a9408cdda24cd8bfd6187fd3159d686ea1)
as n tends to infinity, for any fixed ε > 0. Therefore, the sequence Tn of sample means is consistent for the population mean μ (recalling that Φdisplaystyle Phi 
Establishing consistency
The notion of asymptotic consistency is very close, almost synonymous to the notion of convergence in probability. As such, any theorem, lemma, or property which establishes convergence in probability may be used to prove the consistency. Many such tools exist:
- In order to demonstrate consistency directly from the definition one can use the inequality [3]
- Pr[h(Tn−θ)≥ε]≤E[h(Tn−θ)]h(ε),displaystyle Pr !big [h(T_n-theta )geq varepsilon big ]leq frac operatorname E big [h(T_n-theta )big ]h(varepsilon ),
- Pr[h(Tn−θ)≥ε]≤E[h(Tn−θ)]h(ε),displaystyle Pr !big [h(T_n-theta )geq varepsilon big ]leq frac operatorname E big [h(T_n-theta )big ]h(varepsilon ),
![displaystyle Pr !big [h(T_n-theta )geq varepsilon big ]leq frac operatorname E big [h(T_n-theta )big ]h(varepsilon ),](https://wikimedia.org/api/rest_v1/media/math/render/svg/2f85b6918244bbc21064136cadbed4a801549fad)
the most common choice for function h being either the absolute value (in which case it is known as Markov inequality), or the quadratic function (respectively Chebyshev's inequality).
- Another useful result is the continuous mapping theorem: if Tn is consistent for θ and g(·) is a real-valued function continuous at point θ, then g(Tn) will be consistent for g(θ):[4]
- Tn →p θ ⇒g(Tn) →p g(θ)displaystyle T_n xrightarrow p theta quad Rightarrow quad g(T_n) xrightarrow p g(theta )
- Tn →p θ ⇒g(Tn) →p g(θ)displaystyle T_n xrightarrow p theta quad Rightarrow quad g(T_n) xrightarrow p g(theta )

Slutsky’s theorem can be used to combine several different estimators, or an estimator with a non-random convergent sequence. If Tn →dα, and Sn →pβ, then [5]
- Tn+Sn →d α+β,TnSn →d αβ,Tn/Sn →d α/β, provided that β≠0displaystyle beginaligned&T_n+S_n xrightarrow d alpha +beta ,\&T_nS_n xrightarrow d alpha beta ,\&T_n/S_n xrightarrow d alpha /beta ,text provided that beta neq 0endaligned
- Tn+Sn →d α+β,TnSn →d αβ,Tn/Sn →d α/β, provided that β≠0displaystyle beginaligned&T_n+S_n xrightarrow d alpha +beta ,\&T_nS_n xrightarrow d alpha beta ,\&T_n/S_n xrightarrow d alpha /beta ,text provided that beta neq 0endaligned

- If estimator Tn is given by an explicit formula, then most likely the formula will employ sums of random variables, and then the law of large numbers can be used: for a sequence Xn of random variables and under suitable conditions,
- 1n∑i=1ng(Xi) →p E[g(X)]displaystyle frac 1nsum _i=1^ng(X_i) xrightarrow p operatorname E [,g(X),]
- 1n∑i=1ng(Xi) →p E[g(X)]displaystyle frac 1nsum _i=1^ng(X_i) xrightarrow p operatorname E [,g(X),]
![frac 1nsum _i=1^ng(X_i) xrightarrow p operatorname E[,g(X),]](https://wikimedia.org/api/rest_v1/media/math/render/svg/10b736680a0d0837ea1290104d9acca589aa63f4)
- If estimator Tn is defined implicitly, for example as a value that maximizes certain objective function (see extremum estimator), then a more complicated argument involving stochastic equicontinuity has to be used.[6]
Bias versus consistency
Unbiased but not consistent
An estimator can be unbiased but not consistent. For example, for an iid sample x
1,..., x
n one can use T
n(X) = x
n as the estimator of the mean E[x]. Note that here the sampling distribution of T
n is the same as the underlying distribution (for any n, as it ignores all points but the last), so E[T
n(X)] = E[x] and it is unbiased, but it does not converge to any value.
However, if a sequence of estimators is unbiased and converges to a value, then it is consistent, as it must converge to the correct value.
Biased but consistent
Alternatively, an estimator can be biased but consistent. For example, if the mean is estimated by 1n∑xi+1ndisplaystyle 1 over nsum x_i+1 over n

Important examples include the sample variance and sample standard deviation. Without Bessel's correction (that is, when using the sample size n instead of the degrees of freedom n − 1), these are both negatively biased but consistent estimators. With the correction, the corrected sample variance is unbiased, while the corrected sample standard deviation is still biased, but less so, and both are still consistent: the correction factor converges to 1 as sample size grows.
Here is another example. Let Tndisplaystyle T_n

- Pr(Tn)={1−1/n,if Tn=θ1/n,if Tn=nδ+θdisplaystyle Pr(T_n)=begincases1-1/n,&mboxif T_n=theta \1/n,&mboxif T_n=ndelta +theta endcases

We can see that Tn→pθdisplaystyle T_nxrightarrow ptheta 
![displaystyle operatorname E [T_n]=theta +delta](https://wikimedia.org/api/rest_v1/media/math/render/svg/88d36066b1ca8f168ef6c72d6650e8eedcf80d22)
See also
- Efficient estimator
Fisher consistency — alternative, although rarely used concept of consistency for the estimators- Regression dilution
- Statistical hypothesis testing
Notes
^ Amemiya 1985, Definition 3.4.2.
^ Lehman & Casella 1998, p. 332.
^ Amemiya 1985, equation (3.2.5).
^ Amemiya 1985, Theorem 3.2.6.
^ Amemiya 1985, Theorem 3.2.7.
^ Newey & McFadden 1994, Chapter 2.
References
Amemiya, Takeshi (1985). Advanced Econometrics. Harvard University Press. ISBN 0-674-00560-0..mw-parser-output cite.citationfont-style:inherit.mw-parser-output .citation qquotes:"""""""'""'".mw-parser-output .citation .cs1-lock-free abackground:url("//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Lock-green.svg/9px-Lock-green.svg.png")no-repeat;background-position:right .1em center.mw-parser-output .citation .cs1-lock-limited a,.mw-parser-output .citation .cs1-lock-registration abackground:url("//upload.wikimedia.org/wikipedia/commons/thumb/d/d6/Lock-gray-alt-2.svg/9px-Lock-gray-alt-2.svg.png")no-repeat;background-position:right .1em center.mw-parser-output .citation .cs1-lock-subscription abackground:url("//upload.wikimedia.org/wikipedia/commons/thumb/a/aa/Lock-red-alt-2.svg/9px-Lock-red-alt-2.svg.png")no-repeat;background-position:right .1em center.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registrationcolor:#555.mw-parser-output .cs1-subscription span,.mw-parser-output .cs1-registration spanborder-bottom:1px dotted;cursor:help.mw-parser-output .cs1-ws-icon abackground:url("//upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Wikisource-logo.svg/12px-Wikisource-logo.svg.png")no-repeat;background-position:right .1em center.mw-parser-output code.cs1-codecolor:inherit;background:inherit;border:inherit;padding:inherit.mw-parser-output .cs1-hidden-errordisplay:none;font-size:100%.mw-parser-output .cs1-visible-errorfont-size:100%.mw-parser-output .cs1-maintdisplay:none;color:#33aa33;margin-left:0.3em.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration,.mw-parser-output .cs1-formatfont-size:95%.mw-parser-output .cs1-kern-left,.mw-parser-output .cs1-kern-wl-leftpadding-left:0.2em.mw-parser-output .cs1-kern-right,.mw-parser-output .cs1-kern-wl-rightpadding-right:0.2em
Lehmann, E. L.; Casella, G. (1998). Theory of Point Estimation (2nd ed.). Springer. ISBN 0-387-98502-6.
Newey, W. K.; McFadden, D. (1994). "Chapter 36: Large sample estimation and hypothesis testing" (PDF). In Robert F. Engle and Daniel L. McFadden (eds.). Handbook of Econometrics. 4. Elsevier Science. ISBN 0-444-88766-0.CS1 maint: Uses editors parameter (link)
Nikulin, M. S. (2001) [1994], "Consistent estimator", in Hazewinkel, Michiel (ed.), Encyclopedia of Mathematics, Springer Science+Business Media B.V. / Kluwer Academic Publishers, ISBN 978-1-55608-010-4
Sober, E. (1988), "Likelihood and convergence", Philosophy of Science, 55: 228–237, doi:10.1086/289429.
External links
Econometrics lecture (topic: unbiased vs. consistent) on YouTube by Mark Thoma
